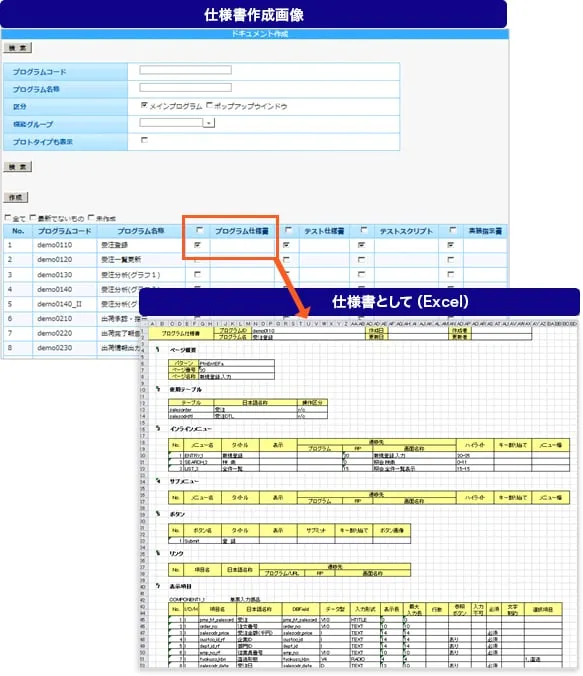
リポジトリ(Repository)
リポジトリ(Repository)は1980年代にCASEツールを統合するために登場しました。リポジトリ登場の背景からその現在まで、ソフトウェアエンジニアリングの歴史を振り返りながら、リポジトリを解説します。
リポジトリ(Repository)とは
リポジトリ(repository)とは英語で「貯蔵庫」、「倉庫」などを表す言葉で、一般用語としては、さまざまなデータ、情報、知識や成果物を蓄積するデータベースやアーカイブを指します。世の中には○○リポジトリ、××リポジトリといった分野別の大規模知識データベースやソフトウェアアーカイブが存在します。例えば、研究機関が研究成果や学術情報を蓄積する機関リポジトリやCVS(Concurrent Versions System)、SVN(Apache Subversion)、GitHubのようなバージョン管理機能を持つソースコード管理システムなどが有名です。
一方、ソフトウェアエンジニアリングの世界では、リポジトリは情報システムの開発工程にかかわる情報、さらには開発工程だけでなく、プロジェクト計画、プロジェクト管理、保守、運用などソフトウェアのライフサイクル全般にわたる情報を定義、蓄積し、管理するための機能やメカニズムを指します。
リポジトリは1980年代に複数のCASEツール(Computer-Aided Software Engineering Tools)とデータディクショナリ(Data Dictionary)を統合するものとして登場しました。特にこれをCASEリポジトリといいます。その後、リポジトリの概念は企業全体、ソフトウェア・ライフサイクル全体に拡張されていきました。
リポジトリ(Repository)の歴史的背景
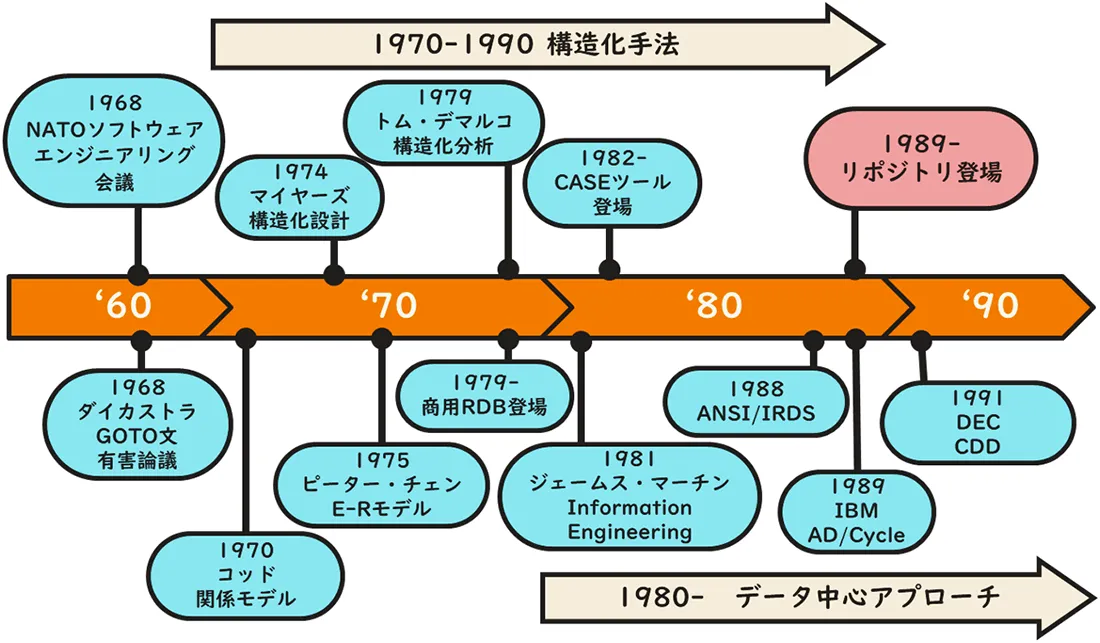
リポジトリは1980年代後半、それまでの構造化手法、インフォメーション・エンジニアリング(データ中心アプローチ)、データディクショナリ、CASEツールというソフトウェアエンジニアリング技術の進展の中で登場しました。そこで、リポジトリを理解するために、1960年代後半から1990年代初めまでのソフトウェアエンジニアリング事情を振り返ってみましょう。
ソフトウェアエンジニアリングの始まり

「ソフトウェアエンジニアリング」が始まったのは、1968年にドイツのガルミッシュで「Software Engineering」という同名の国際会議が開催されてからと言われています。同会議はNATOの科学委員会が主催し11カ国が参加しました。当時世界では、1964年にリリースされたIBMの最初の汎用コンピュータSystem/360上で大規模なシステム開発が始まっていました。複雑化するシステム開発に対し、システムの信頼性を確保しつつ納期通りにリリースすることが困難になり、軍事的にも大きな問題となっていたのです。同会議ではこれを「ソフトウェア危機」と呼びました。
構造化手法の広まり
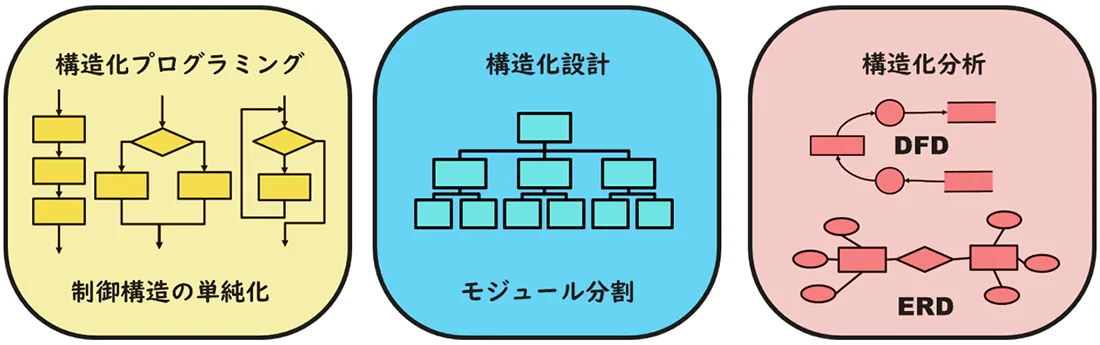
1970年代には「構造化手法」が花開きます。構造化手法とは開発技術者個人の知識と技量への依存を極力排除し、開発チーム全体で理解して実行できる工学的な方法論に則って開発を行おうというものです。
まず、構造化プログラミングがオランダのエドガー・ダイカストラ(Edsger A.Dijkstra)による「GOTOステートメントは有害だ」という議論から始まりました。GOTOステートメントの使用密度が高いほどプログラムの品質が低下するというのです。やがて、ひとかたまりの処理の入り口と出口をひとつにし、アルゴリズムを「順次」、「選択」、「反復」の3つの組み合わせだけでプログラムを構築することが推奨されます。「構造化定理」はこの3つの制御だけでいかなるフローチャートも表現できることを数学的に証明しました。
次に、米国のグレンフォード・マイヤーズ(Glenford J. Myers)により、アプリケーション機能を階層的に配置された独立性が高く理解しやすいモジュールに細分化していく構造化設計が完成します。大きなプログラムをシンプルな構造の小さなモジュールに分割して構築することで、見通しをよくして開発やテストを簡単にしようというのです。
その後、構造化手法はトム・デマルコ(Tom DeMarco)のDFD(Data Flow Diagram)とデータディクショナリ(Data Dictionary)、ピーター・チェン(Peter Chen)のER図(Entity Relationship Diagram)、さらに状態遷移図などにより上流工程の構造化分析まで広がりました。
それまで、プログラマやSE個人の職人芸だったソフトウェア開発を、論理的、工学的なものに変えようというこの試みは世界中広く普及しました。
ところが、構造化手法にも弱点がありました。構造化手法はアプリケーション単位に、①出力データ、②入力データ、③処理の順に注目します。すなわち、①目的とする画面、帳票、ファイル出力を実現するためには、②どのような入力データが必要で、③どのように処理するのが最も効率がいいかという観点で最適化します。
このようにしていくと、アプリケーション毎に最適化されたデータベースが次々に構築され、アプリケーション間でデータの重複が発生します。例えば、製品名や価格などがあちらこちらの場所に違う名称、場合によっては違う桁数でコピーされるのです。
システム保守に伴う機能追加の中でコピーは繰り返され、中には使われなくなるものも多く発生しました。データが重複すれば、その整合性を維持確認するプログラムも余計に必要になります。データとプログラムは増え続け、システム保守にかかる工数が膨れ上がっていったのです。
インフォメーション・エンジニアリング(データ中心アプローチ)
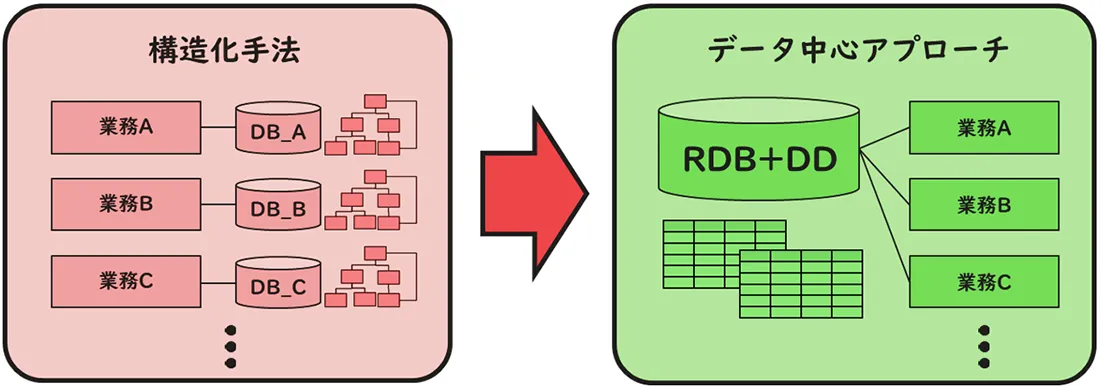
1970年にエドガーF.コッド(Edgar F.Codd)の関係モデルに関する論文が発表され、1975年にはピーター・チェン(Peter Chen)のE-Rモデルに関する論文が発表されました。1980年代には、これらの理論を基に、それまでの階層型、及びネットワーク型データベースに変わるリレーショナルデータベース(RDB:Relational Data Base)が市場に出てきました。
リレーショナルデータベースの登場に伴い、処理に対し比較的安定したデータを中心にシステムを考えるデータ中心アプローチ、DOA(Data Oriented Approach)が広まりました。ちなみに、DOAは和製英語で、英語ではインフォメーション・エンジニアリング(IE:Information Engineering)といいます。
インフォメーション・エンジニアリングはオーストラリアのクライブ・フィンケルシュタイン(Clive Finkelstein)が始め、その後、ジェームス・マーティン(James Martin)が体系にまとめました。インフォメーション・エンジニアリングでは企業戦略に基づき、ビジネス分析、システム設計、システム構築というようにトップダウンでデータやプロセスを捕捉していきます。その中でデータモデリングも提案されています。
日本のデータ中心アプローチの手法としては1975年に椿正明氏がTH法を発表したのが始まりです。その後、佐藤正美氏がT字形ER手法(現在のTM)、渡辺幸三氏が三要素分析法など独自の手法を発表しました。それぞれ手法は違いますが、データベースを個々のアプリケーションとは独立させ、体系化していく点では共通しています。
インフォメーション・エンジニアリングに呼応するように市場にはデータディクショナリ(DD Data Dictionary)を搭載したデータベース製品が登場するようになりました。データディクショナリはデータベースのスキーマやデータ項目を一元管理する機能です。
ただし、データディクショナリは製品毎に仕様が異なっていたため、企業レベルでデータ項目を一元管理できません。そこで、1988年にANSI(American National Standards Institute)が標準ディクショナリとしてANSI/IRDS(Information Resource Dictionary System)を発表しました。
インフォメーション・エンジニアリングはその後、クライブ・フィンケルシュタインやジェームス・マーティンらによって、RAD(Rapid Application Development)、CASE(Computer-Aided Software Engineering)やEA(Enterprise Architecture)などにつながっていきます。
リポジトリの登場
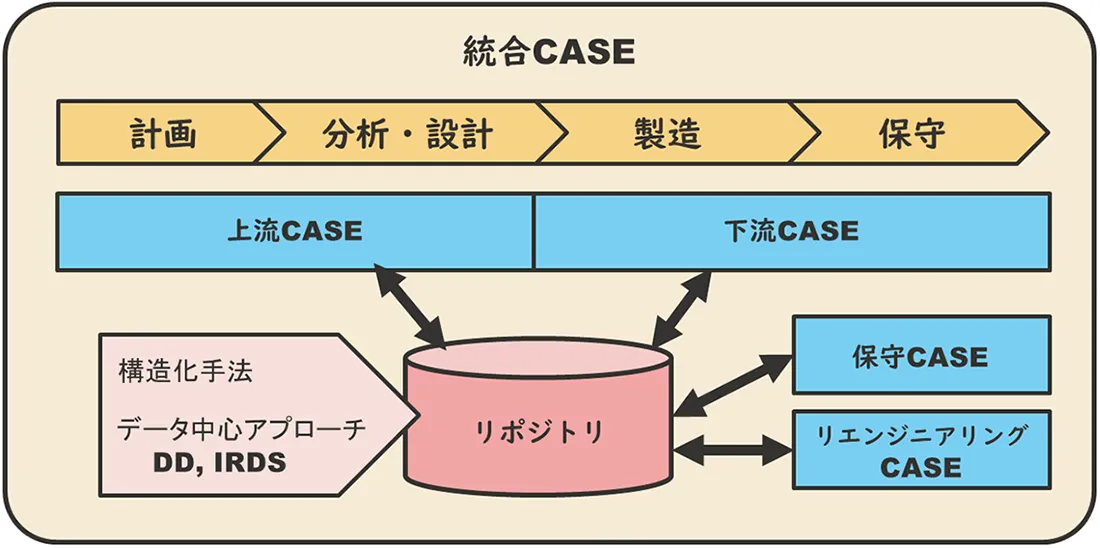
1980年代中盤からは、ソフトウェアエンジニアリングを自動化するツールとしてCASE(Computer-Aided Software Engineering)ツールが登場します。
CASEの思想は、構造化手法による計画、分析・設計、製造、保守の各工程をひとつのプラットフォーム上で一貫してコンピュータで支援することにより、情報の一貫性を保ち、データの二重入力をなくし、製造の自動化につなげようとするものです。
CASEツールは当初GUIを駆使してさまざまなダイアグラムを作成するツール、プログラムを自動生成するツールなど、個別の開発支援ツールでした。それがCASEの思想に基づいて統合されていったのです。それでも、分析・設計を支援する上流CASEツール(Upper CASE)と構築・保守を支援する下流CASEツール(Lower CASE)は統合されませんでした。
上流と下流でCASEツールが別々に分かれていたため、開発に関する情報伝達も分断されていました。そこで、ソフトウェア・ライフサイクルの全工程を支援できる統合CASEツールを実現するために、既存のCASEツールを統合することが考えられました。この時、CASEツールを統合するための最も重要なピースがリポジトリだったのです。
1989年IBM社は多くのCASEツールを統合する統合CASEツールとしてAD/Cycleを発表しました。AD/Cycleの中でリポジトリはCASEツールを統合する中心的な役割を担っていました。IBMのリポジトリは独自仕様でDB2上に保持され、DB2のデータディクショナリも統合しました。IBMはOS/2やメインフレームのIBM DB2で稼働するリポジトリにより、各社とアライアンスを結びAD/Cycleを広めていきます。
一方、DEC社はCDD/Repository(Common Data Dictionary/Repository)というリポジトリを発表、こちらはオープンアーキテクチャーでデータディクショナリ部分はANSI/IRDSに準拠した内容でIBMに対抗しました。
CASEツールは1990年代初めにピークを迎えますが、その後、クライアントサーバシステムの台頭によりメインフレーム上で稼働するAD/Cycleや大規模なCASEツールは衰退し、それに伴いCASEリポジトリも姿を消していきました。
IBMはクライアントサーバ技術に舵を切り、CASEリポジトリの技術はCMVC(Configuration Management Version Control)、すなわち成果物の構成管理、バージョン管理ツールにその後姿を変えてRational製品群に投入されていきました。
リポジトリの構成
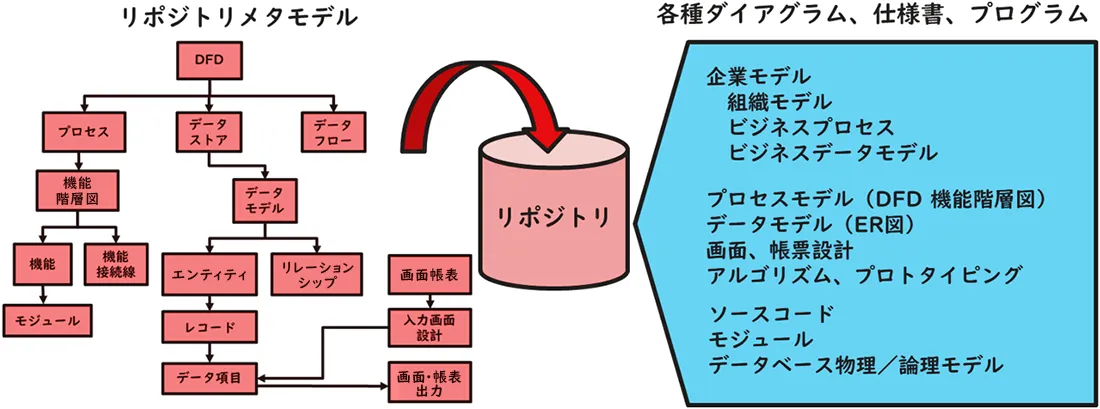
リポジトリに保持される情報
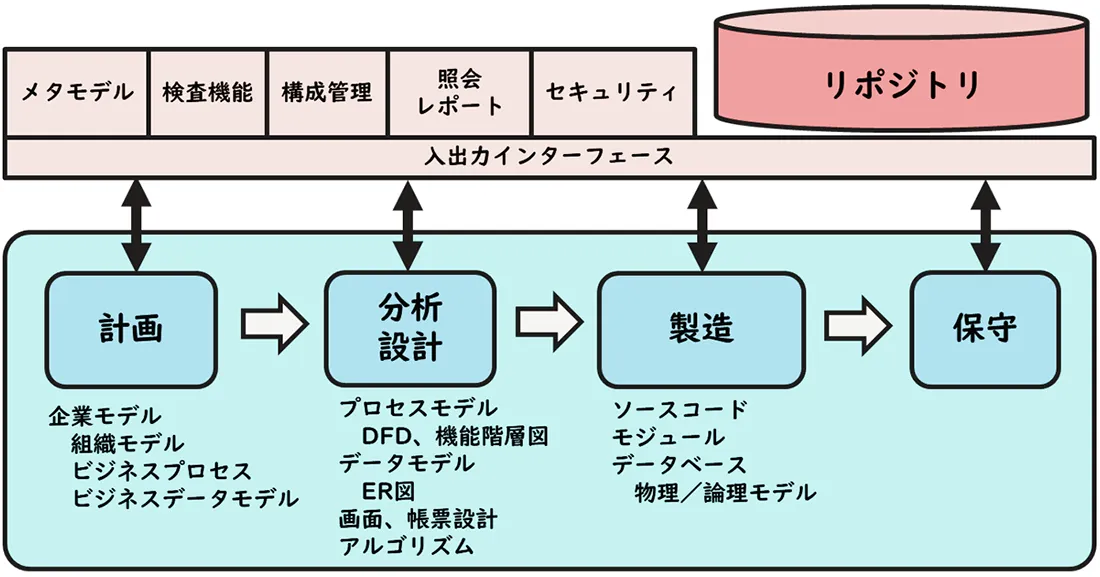
リポジトリ(CASEリポジトリ)は各種CASEツールを統合し、ソフトウェア・ライフサイクルで必要な多岐に渡る情報を保持し整合性を維持します。
CASEツールのソフトウェア・ライフサイクルは大きく4つに分かれています。
- 計画段階
- 分析・設計段階
- 製造段階
- 保守段階
リポジトリはソフトウェア・ライフサイクルの各工程で作成されるデータモデルやプロセスモデルの構成要素を保持し、整合性を維持します。
計画段階では、トップダウン手法により企業モデルを作成し、そこからビジネスプロセスとビジネスデータを捕捉しダイアグラム形式で登録します。分析・設計段階では計画段階で捕捉したデータとプロセスをさらに階層的に細分化していきます。一方、業務分析やプロトタイピング手法によるボトムアップ手法により現場レベルのデータとプロセスも捕捉していきます。これらを突き合わせて全体のプロセスモデルとデータモデルを作成します。製造段階ではデータベースを物理実装し、プログラムソースコードの自動生成機能を活用してプログラム開発を進めます。保守段階では機能追加・変更に伴い、上記の情報に追加・変更を加えていきます。
リポジトリはこの各工程における情報の構成要素に加えて、それら構成要素間の関連を保持しています。例えば、組織モデルにおける組織の階層構造やプロセスモデルにおけるDFDや機能階層図の関係線など、さまざまなダイアグラムの構成要素間の関連も保持しているのです。
さらに、構成要素の正当性をチェックするための規則(例えば、データモデルやプロセスモデルなどのダイアグラムの表記規則、命名規則等)も保持しています。こうすることによって、リポジトリ内の情報の一貫性、完全性を保証しているのです。
| 工程 | 作成される情報 |
|---|---|
| 計画段階 | 企業モデル(組織モデル、ビジネスプロセスモデル、ビジネスデータモデル) |
| 分析・設計段階 | プロセスモデル(DFD、階層図)、データモデル(ER図)、画面や帳表の定義、アルゴリズム(プロトタイプ) |
| 製造段階 | プログラムソースコード、実行モジュール、データベース物理モデル、論理モデル |
| 保守段階 | 上記の変更・追加 |
リポジトリの定義(リポジトリ・メタモデル)
リポジトリはソフトウェア・ライフサイクルにおける情報の構成要素や構成要素間の関連を保持し、複数のCASEツールやデータディクショナリを統合しますが、それらの情報は、例えば上流のCASEツールと下流のCASEツールが同じ情報を理解できるように再構成可能でなければなりません。
例えば、リポジトリはさまざまなダイアグラムを保持しますが、図をビットマップ等のイメージとして保持するのではなく、そのダイアグラムに含まれるオブジェクトやオブジェクト間の関連として保持します。すなわち、ダイアグラムの意味を保持するのです。そうすることによって、さまざまなCASEツールに対しそのツールが理解できるビューを提供します。
このリポジトリに保持される構成要素や関連の保持形態を定義しているのがリポジトリ・メタモデルです。
ところで、メタモデルとは何でしょうか。データモデルを例にしてみましょう。
例えば、「楽々楽介」、「男」、「32(歳)」というのはデータです。これに対し、「氏名」、「性別」、「年齢」などの属性名をメタデータと言います。「メタ」というのは、ある情報を1段抽象化した情報を指します。メタデータを集めて構造化したものをデータモデルと呼んでいますが、エンティティの構成やエンティティ間のリレーションシップ表現方法など、データモデルの形式を表す情報をメタモデルと呼びます。
リポジトリはさまざまなメタデータを集めたメタデータベースとも言われます。それを定義しているのがリポジトリ・メタモデルです。多くのリポジトリ・メタモデルはE-Rモデルで記述されています。中にはオブジェクト指向モデルを併用しているものもあります。
E-Rモデルとは情報をエンティティとその関連を表すリレーションシップで記述していく方法です。例えば、データモデルのER図もE-Rモデルのひとつです。また、組織モデルにおいて、組織の部署間の関係や、部署と従業員の関係はエンティティとリレーションシップで表現されます。さらに、プログラムとサブプログラムの関係、プロセスのプロセス間の関係もエンティティとリレーションシップで表されます。エンティティやリレーションにはさまざまな種類がありそれを「タイプ」といいます。このように、E-Rモデルは応用範囲の広いモデリング手法です。
E-Rモデルはさまざまなモデル記述に活用され、その格納先としてリレーショナルデータベースが採用されていたため、多くのリポジトリ・メタモデルはE-Rモデルで記述されていました。
リポジトリの機能
本来、CASEツールではソフトウェア・ライフサイクルの上流で入力した情報を下流で再入力することなしに利用することが可能です。さらに、上流あるいは下流で情報の追加・変更・削除等があった場合でも、全体の整合性が保たれるようになっています。
ところが、多くのCASEツールは上流CASEツールと下流CASEツールに分断され、場合によってはベンダーも異なっていました。さらに保守工程を専門に扱うCASEツール、リエンジニアリングを専門行うCASEツールなどさまざまなCASEツールが存在していました。
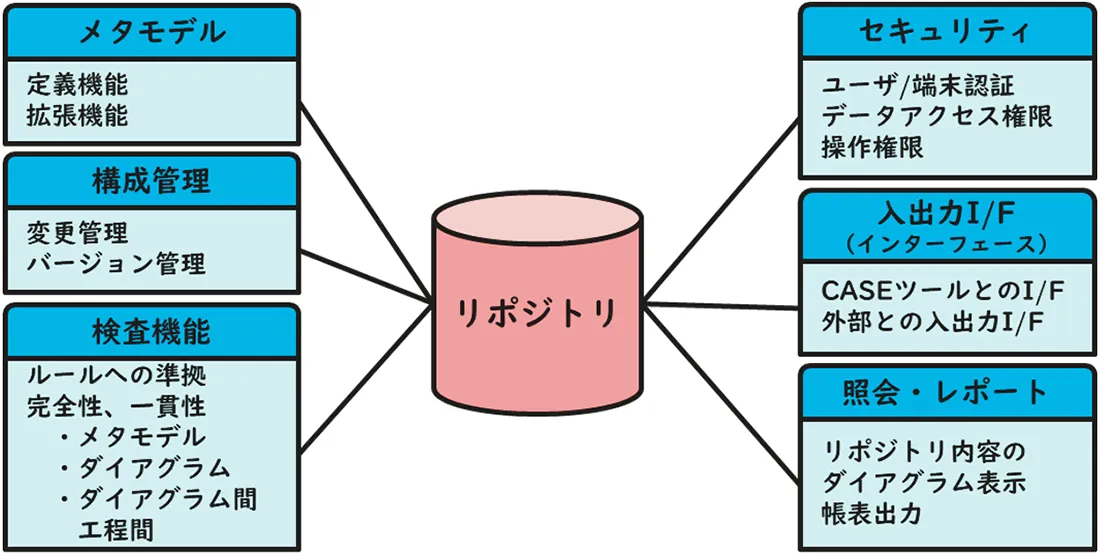
これらのCASEツールを統合するための中核的な機能がリポジトリです。リポジトリには、複数のCASEツール間で情報を橋渡しするとともに、全体整合性を保つ機能が求められます。従って、リポジトリにおいては、登録データの完全性を保つ検査機能が非常に重要です。
検査機能では、大きく3つの観点から情報を検査します。まず、①メタモデルの定義やルールに合致しているか、すなわち、エンティティやオブジェクトのタイプや属性がルールに則しているか、リレーションシップのタイプやカーディナリティ(1対1、1対多、多対多)がルールに則しているかをチェックします。次に、②個別のダイアグラムのその記述ルール、例えばDFDならその記述ルールに合致しているかをチェックします。最後に③ダイアグラム間や工程間で情報の一貫性が保たれているかをチェックします。
構成管理機能では主にバージョン管理と変更管理を行います。バージョン管理はリポジトリ内の複数の構成要素のセット、すなわち複数のソフトウェアバージョンを保持し管理する機能です。これにより複数バージョンの開発を同時並行で進めることが可能になります。変更管理では、構成要素に対するあらゆる追加・変更・削除等の変更履歴を記録します。変更履歴には監査で利用できるように操作者や操作時間などの情報も同時に記録されます。さらに、その変更が及ぼす影響範囲を示し、必要な更新に漏れがあれば警告し、場合によっては自動更新します。例えば、画面やデータ項目が削除された場合に、関連ずる情報の画面やデータ項目を削除する等です。構成管理機能は任意のバージョンを整合性のとれた状態で再現することを可能にします。
リポジトリが持つ主な情報管理機能を下記にまとめます。
| 機能 | 概要 |
|---|---|
| メタモデルの定義 | E-Rモデルでメタモデルを定義し保存する機能。必要に応じてE-Rモデルで表示する機能。メタモデルを拡張する機能。製品によってはオブジェクト指向でのメタモデル拡張機能を持つ。 |
| 検査 | ルールへの準拠、一貫性、完全性のチェック機能
|
| リポジトリへの入出力 | 各CASEツール、リエンジニアリングツール等がリポジトリにアクセスするためのインターフェース(ビュー)の提供。あるいは、その他、外部とのデータ入出力インターフェースの提供 |
| 構成管理 | 変更履歴の記録や影響範囲をチェックする変更管理機能、複数バージョンを保持するためのバージョン管理機能 |
| 照会、レポート出力 | リポジトリの内容をそれぞれのダイアグラムの形式で画面に表示し、レポート形式で帳票出力する機能 |
| セキュリティ | 端末やユーザ毎のログイン認証、各データへのアクセス許可、操作権限の体系を保持し適用する機能 |
リポジトリのその後
現在、ITの世界でリポジトリと言えば、CVS、SVN、GitHub等のソースコードのバージョン管理システムやオープンソースソフトウェアのアーカイブを思い浮かべる人が多いでしょう。かつてのように、リポジトリを頂点に企業のさまざまな情報を統合し、ソフトウェア開発、保守・運用を支援するという流れは下火になりました。
一方、企業レベルでメタデータを管理し、データやプロセスを統合的に扱おうとする動きは、EA(Enterprise Architecture)やERP(Enterprise Resource Planning)に引き継がれていきました。
EAは、ジョン・A・ザックマン(John A.Zachman)が1987年に発表したザックマンFrameworkに始まり、その後改良を経て1990年頃から普及が始まりました。EAは①ビジネス、②データ、③アプリケーション、④テクノロジーの4つの観点で企業の情報システム全体を可視化し最適化しようとするものです。リポジトリよりも広い範囲を対象にしています。
ERPは既に1970年頃から存在していましたが、BPR(Business Process Reengineering)が流行した1990年頃から急速に普及しました。ERPは経理システム、人事システム、生産管理システム、販売管理システムなど企業のほとんどの基幹システムを統合されたひとつのアーキテクチャーで実現します。EAを実現する手っ取り早い方法です。
一方、ソフトウェア開発においては、最近、超高速開発/ローコード開発のような分野で、リポジトリからプログラムの自動生成を行うようなツールが数多く存在します。IT技術者が不足する中、デジタルトランスフォーメーションで増大するソフトウェア開発要求に対応するために、短期間でソフトウェアをリリースできる手段が従来に増して求められているのです。
参考文献
- Edsger Dijkstra(1968)「Communications of the ACM11,3(March 1968).147-148」
- Peter Naur and Brian Randell (1969) 「Report on a conference sponsored by the NATO SCIENCE COMMITTEE Garmisch, Germany, 7th to 11th October 1968」Scientific Affairs Division NATO Brussels 39 Belgium
- 佐藤正美(1989)「CASEツール-機能解説と活用のノウハウ」ソフト・リサーチ・センター
- 佐藤正美(1991)「リポジトリ入門解説―技術体系と活用ガイド」ソフト・リサーチ・センター
- カーマ・L・マクルーア(1993) 「ソフトウェア開発と保守の戦略―リエンジニアリング・リポジトリ・再利用」共立出版
- 椿正明(2000)「データ中心アプローチによる情報システムの構築」オーム社出版
- 渡辺幸三(2003)「業務システムのための上流工程入門」 日本実業出版
- 佐藤正美(2005)「「データベース設計論 T字形ER ~関係モデルとオブジェクト指向の統合をめざして~」ソフト・リサーチ・センター
関連記事
データモデリング:佐藤正美氏、若手エンジニアにデータモデリングを語る!
https://www.sei-info.co.jp/framework/column/data-modeling/
ローコード開発プラットフォーム:ローコード開発プラットフォームとは?
https://www.sei-info.co.jp/framework/column/lowcode-platform/
ローコード開発:ローコード開発ツール「楽々Framework3」とは?
https://www.sei-info.co.jp/framework/scene/low-code-development-tools/
基幹システム:基幹システムとERP
https://www.sei-info.co.jp/framework/column/enterprise-system/