データモデリング~佐藤正美氏、若手エンジニアにデータモデリングを語る~

株式会社エス・ディ・アイ代表
佐藤 正美(さとう まさみ)氏

インタビュア:住友電工情報システム株式会社
磯部 純也(いそべ じゅんや)
目次
データモデリングとは
データモデリングとは、ある方法論に従ってデータを構造化していくことであり、広義にはリレーショナル・データベースだけでなく、あらゆるデータソース(文書ファイル、ハイパーテキスト、オブジェクトデータ等)と関連付けの方法による構造化が対象となりますが、狭義にはリレーショナル・データベースの関係モデル(関数従属性)を使って事業のデータ構造を表すことです。ここでは特に断らない限り狭義の意味で用いることとします。
かつて、データ構造がアプリケーションの都合により左右される時代もありましたが、データモデリングの普及により、データがアプリケーションから独立していることが重視されるようになりました。いわゆるDOA(Data Oriented Approach)です。近年、オブジェクト指向、アジャイルソフトウェア開発、クラウド、ビッグデータ、NoSQL、IoTなど様々なアプリケーション開発手法やリレーショナル・データベース以外のデータソースの台頭により、データ構造を慎重に設計してデータベースを構築するよりも、既にストアされたデータをアプリケーションの工夫によりすべて処理してしまおうとする傾向が強くなっています。それに従い、データモデリングを真剣に学ぶ若手のIT技術者が減少しているように思われます。
しかしながら、情報システムの要は今も昔もデータベースでありデータモデリングの重要性に変わりはありません。そこで、日本の代表的なデータモデリング手法である「TM(T字形ER手法)」を考案された佐藤正美氏に、若手のITエンジニアとデータモデリングについて語っていただきました。
データモデリングとデータベース設計の違い
~「L-真」と「F-真」~
佐藤正美さん、ご多用のところまことにありがとうございます。住友電工情報システム(株)の磯部です。本日は、デーモデリングやTM(T字形ER手法)についてお聞きしたいことが山ほどあります。よろしくお願いします。
こちらこそ、よろしくお願いします。
住友電工情報システム(株)では、入社時に技術者全員がTM(T字形ER手法)の教育を受け、ER図を描いていますが、データモデリングとは呼ばずデータベース設計と呼んでいます。そもそもデータモデリングとデータベース設計の考え方は同じなのでしょうか。
違います。世間ではどうかわかりませんが、データモデリングとデータベース設計は違います。
具体的にどのあたりが違うのですか。
まず、データモデリング、データベース設計を比べるとデータベース設計の方がより実装に近くなります。TMの用語で言えば、データベース設計は「L-真」レベルまで、データモデリングは「L-真」に加えて「F-真」レベルまで実施します、さらにデータモデリングでは関係の網羅性、制約・束縛の網羅性を保証します。
その「L-真」、「F-真」について少し詳しく教えてください。
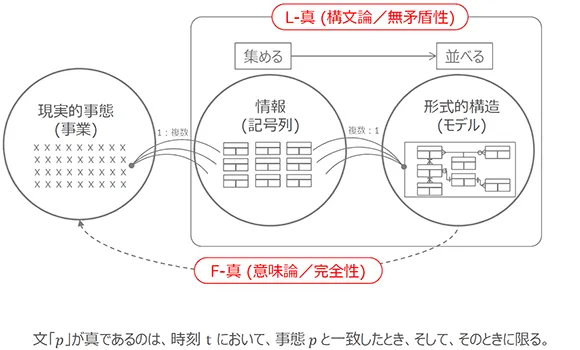
データモデリングをするために重要な概念が「L-真」と「F-真」です。
「L-真」というのは、「Logicで正しい(真である)」という意味です。例えば、自然数を例にすれば、「1」をインプットにして「3」をアウトプットするためのアルゴリズムを考える(プログラムあるいは関数を作成する)とすれば、「1+1+1」でもいいし、「1×3」でもいい──2つのうち、どちらかが間違っている訳ではない。両方とも無矛盾です。つまり、「L-真」というのは、無矛盾であっても、幾つもやり方があるということです。データモデルで言えば、「関係」の文法に従っても、幾つもの無矛盾なデータモデルが作成できるということです。
「F-真」というのは「Factと一致して正しい(真である)」ということ。「事実」は、一つです。だから、「事実」を写像するデータモデルも一つです。「関係」文法に従って作成されたデータモデルは──言い換えれば、文法違反していないデータモデルは──必ず「L-真」です。ところが、それが「F-真」であることは限らない。なぜなら、「L-真」のデータモデルは、いくつも作成できるからです。
「事実」は一つだから。いくつもの可能な「L-真」のデータモデルのなかで、「F-真」のデータモデルは一つしかない。データモデリングという場合は、それが現実の事業構造を写像した形で一対一になっていなければならない。
その「F-真」、「L-真」というのはTMの用語ですか。
いいえ、用語自体はドイツの哲学者のカルナップのものです。カルナップの概念をデータモデルに当てはめるために少し工夫しています。TMでは、事業で合意、認知され使われている共有語を集めてentityを生成し、関係の規則に従って構造化したものが「L-真」、その中でさらに現実の事業を指示するものが「F-真」です。
佐藤正美さんの著書やセミナーの中ででも頻繁に「L-真」で描いてから、「F-真」をとるという表現をされていますね。「L-真」のデータモデルは複数あるけれども、「F-真」のデータモデルはひとつしかないというような具体的な業務例はありませんか。
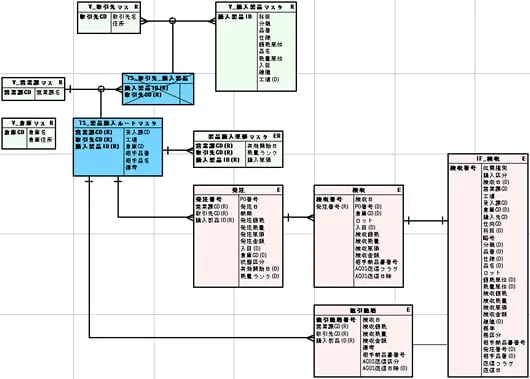
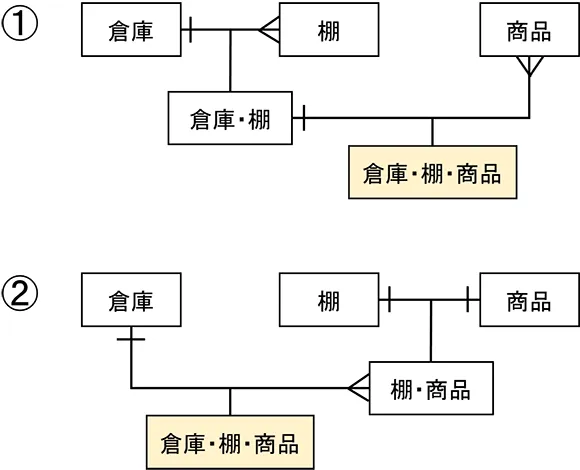
いくらでもあります。簡単な例が在庫です。いま、「倉庫」、「棚」、「商品」というエンティティを考えると、例えば、①のように、「倉庫」-「棚」の関係をとって(対照表)、それと「商品」と関係をとる場合。②のように、「商品」と「棚」の関係をとって、それと「倉庫」と関係を取る場合。どちらも、在庫は「商品」、「棚」、「倉庫」を関係の文法に従って構成したデータモデルで表され「L-真」です。最終的な在庫の実装形「倉庫・棚・商品」は全く同じです。ところが①は倉庫に棚をとりつけてそこに商品を据える業務を表しています。②は、台座(棚)に商品を据えてから倉庫に保管するような業務を表します。全く事業が違います。でも事実は一つしかありません。データモデルというのは、その違いまでやります。データベース設計という場合は最終的な実装形までですが、データモデルは「F-真」までやります。データモデルは実際の事業と一対一に対応していなければなりません。
【TM図】
データモデリングでは複数の「L-真」の設計から、事実は何か、どの業務方法がいいかということまで考えるということですね。
もともとは、事業分析とデータベース設計は切り離されていました。事業分析を行ってから、その結果でデータベース設計を実施していたわけです。データベース設計としては、今でも、コッド博士の正規形が最高峰だと思いますが、コッド博士はデータベース設計まででした。コッド博士のデータベース設計からは事業を読むことはできません。事業分析とデータベース設計を同時にできるのがデータモデリングであり、それをできるようにコッド博士のモデルに意味論を強くしたのがTMなのです。
そこまで業務を分析して実態を把握しないと、システム開発において実業務とシステムに乖離が起きてくるということなのですね。「F-真」の設計にするために具体的にはどうすればいいのですか。
技術的には開発の現場で、①関係の網羅性と②制約・束縛の網羅性を保証する必要があります。そのためにはデータモデル図でなければなりません。
- 関係の網羅性:モノ(entity)とモノ(entity)との関係が一つの取りこぼしもなく網羅されている。
- 制約・束縛の網羅性:値が真となるような「取引上の」制約・束縛が網羅されている。
「制約・束縛」とは何をさすのですか。
例えば、受注数の制約・束縛を考えてみます。A社では商品100個を上限としてバラ売りする、B社では30個までバラ売りしてそれ以上はセット販売するという事業がある場合、同じ受注数でもプログラミングが全く変わってきます。このような制約・束縛をすべて洗い出すのです。この関係の網羅性と制約・束縛の網羅性を保証するために、TMというデータモデルを作りました。
このバラ売りかセット販売かというような制約・束縛は具体的にTM図ではどう表現し、どのようにチェックするのですか。
関係の網羅性、すなわち、事業上これとこれとは関係がある、これとこれとは関係がないというのをひとつの取りこぼしもなく網羅するのはデータモデル図でチェックすることができます。一方、制約・束縛の網羅性、すなわち、個々のデータ項目の制約条件はデータモデル図だけではわかりません。TMではそのためにアトリビュートリストを作ってすべてチェックをかけます。
「F-真」を突き詰めてモデリングするのがデータモデリングということですね。データモデリングとデータベース設計の違いがわかったような気がします。データモデルは現実の事業と一対一対応していなければならない。はたして現実の事業は広範囲ですが、データモデリングでどこまで事業分析できるものなのでしょうか。
データモデルは、「事業をプログラミングする」ための資料です。もっと正確に言えば、データモデルとは、現実の事業を写像したもの、言い換えれば、「現実の事業を『論理』を使って形式的構造にした」ものです。したがって、モデルとは、「模型」とか「実例」というふうに言っていい。適切なデータモデルがあれば、事業の「正確な」しくみがわかります。
事業で使われ、意味を伝えている言葉、すなわち共有語(商品コード、商品名…)をすべて集めて、それに事業の構造を与える。共有語に構造を与えたのがモデルです。共有語の裏側にはデータがあるのですなわちデータモデルになります。
佐藤正美さんはよく管理プロセスという言葉を使われますね。
そう、事業において取引のない管理や管理のない取引はありません。すなわち、事業プロセスをモデリングするということは管理プロセスをモデリングすることに他なりません。例えば、製造現場では「サイズ」というモノはありません。ところが台帳など管理プロセスに「サイズ」という言葉があれば、事業で「サイズ」が重要なものとして管理されていることになります。管理プロセスで意味を伝えている言葉、情報をすべて捉えて、それに事業プロセスを写像する構造を与える。そうすることで、事業構造が手に取るようにわかるようになります。

TM(T字形ER手法)誕生!
ところで、TMの、いや最初はT字形ER手法ですね、誕生の経緯をお伺いしたいのですが、まず、素朴な質問ですがTMはそもそも何の略ですか。T字形モデル(T formed Model)でしょうか。
いやいや、Theory of Modelsの略です。最初はTuring Machineを模倣してTMにしようと考えていたのですが、モデル論を勉強したときにTheory of Modelsという言葉があったのでそれにしました。
そのTMを開発された経緯を教えてください。
最初からデータモデルを作成しようとしたのではありません。そもそも私が当初狙っていたのは、RAD(Rapid Application Development、高速開発)です。百万ステップ規模(COBOLなどの手続き言語で百万ステップ)のアプリケーションを10名程度の開発者が6ヶ月で導入することを狙っていました。今でいうAgileに近い。
1980年代当時、その規模の開発には、多数のSE・プログラマーが参加して、1年半から2年を費やしていました。しかし、この1年半や2年という開発期間は、事業の環境変化と著しく乖離していました。そこで、当時、私が狙ったのがRADです。そして、数々のユーザ企業で成功を収めてきたという自負があります。
当時、佐藤正美さん以外に同じような考えでRADを推進していた人はいなかったのでしょうか。
いっぱいいましたよ。特に当時はジェームス・マーティン(James Martin)が提唱するRADが世界を席巻していました。まず、トップダウンでビジネスモデルを作って、次にボトムアップでプロトタイプ的に画面作成などを行う手法です。ところが、ビジネスモデルである機能階層図を作るだけで2ヵ月かかります。6ヵ月で開発することを狙っているのにこれでは間に合わない。だから、事業分析とデータベース設計を同時に行うことを考えたのです。
それは佐藤正美さんが何歳のときですか。
40歳です。
どうして、佐藤正美さんは全く新しい手法であるTMを考案することができたのでしょうか。
米国にいたからかもしれません。幸いにも、私は、当時、日本で先例のなかったRDB(Relational Data Base)を日本に導入普及する仕事をしていました。日本で先例がなかったので、米国でRDBの仕組みを直接指導されました。私は、先ず、RDBの内部構造を指導されました。当時、データベースのほうでは、コッド博士の提唱されたデータ正規形が普及し始めていました。私は、その仕事も担当することになった。
現代のSEが知っているかどうかわからないのですが、RDBはコッド博士の論文を基礎にして作られました。だから、データベースの仕事をするには、コッド論文を読んで、それからRDBを学習するというのが正攻法です。しかし、私の場合、その順序が逆になって、RDBの内部構造を指導されてからコッド論文を学んだ。そのため、実際にプロダクトとしてRDBを作る場合、コッド論文の「弱点(パフォーマンス、資源消費)」を避けてRDBをいかに作るかを私は先に学びました。この点は、幸運でした。コッド正規形の「弱点(データの並び、NULL)」を、コッド論文を読む以前から知っていました。
RDBを使ってRADをやるには、RDBの「弱点」とコッド正規形の「弱点」を回避しなければなりません。そのために、私がやった点は、RDBに対してINDEX-onlyを使い、コッド正規形に対して「意味論」を拡張することでした。コッド正規形に対して「意味論」を拡張したモデルがTMです。TMは、コッド正規形に対して「意味論」を拡張するために生まれました。
RADを実現するためのデータモデルがTMだということですね。実際、住友電気工業(株)では1994年にTMを導入した結果、開発の全行程で生産性が30%向上しました。TMを使えば、アプリケーション開発が楽になる何か具体的な例を教えてください。
端的な例が、住友電工情報システム社主催のモデル作成セミナーでも例を示していますが、1,500ステップから2,000ステップのIFとIF-nestedのプログラムがSELECT数行に改善された例です。これは、大袈裟な話ではなくて、データモデルさえ作成していれば、誰でもできることです。ただし、ここで注意してほしいのは、これはER図(データモデルではない、記法です)を作成しても実現できないという点です。
詳しく知りたいエンジニアは住友電工情報システム社主催のモデル作成セミナーに参加してください(笑)。
TM(T字形ER手法)の特徴
次にTMの特徴について教えてください。
コッド正規形に対して「意味論」を拡張するためにTMが採用した技術は次の6つの体系になっています。
- entityを作る(モノの集まりを作る)
- 「関係」と「関数」(モノを並べる)
- 「関係」文法
- 集合(セット)を作る(Entityを集合として整える)
- 多値関数(くり返し項目を排除する)
- クラス(集合に対してクラスを適用して、モデルを整える)
先ほど言いましたが、我々エンジニアが事業の「意味」を掴まえるのは、ユーザが実際に使っている共有語(記号)に対して形式的構造を与えるのが一番に速い。しかも、形式的構造をつくるには、「単純な一般手続き」でなければなりません。
TMはコッド正規形に対して意味論を拡張したモデルです。拡張した1つがモノ(entity)を、Event(出来事、行為、取引)とResource(出来事に関与するモノ、行為者)に分けたことです。これによって、事業の構造を正確に記述することができます。
そして、モノ(EventとResource)のあいだの関係を次の4つの文法(規則)で記述する。
- EventとResourceのあいだ(出来事に行為者が関与する)
- EventとEventのあいだ(先行・後続関係)
- ResourceとResourceのあいだ(対照表を作成する)
- ひとつの集合の中から幾つかのメンバーを選んで並べる(再帰表を作る)
この文法は誰がやっても同じ結果になる「一般手続き」ですから、データモデルを作るエンジニアの恣意性によってデータモデルが揺らぐことはない。言い換えれば、ひとつ。
簡単なルールというのは理解できますが、本当に誰がやっても同じ結果になるのですか。SEの経験や技量による差異は出ないのでしょうか。
昔、中学生だった息子に簡単なデータモデルを描かせたことがあるが、同じになりました。「お父さんの仕事、簡単だね」と言われました(笑)。ただし、息子はデータモデルが意味するところ、事業の意味を読むことは全くできません。
中学生がやっても同じ結果になるルール通りのモデリングを「構文論」といいます。TMで言えば、「L-真」のレベルです。さらにそこから、「F-真」のレベルまで進めるところは「意味論」と言えます。TMの細かな特徴は、幾つでも述べることができるのですが、この2つの技術(EventとResource、4つの関係文法)さえ習得すれば、データモデルを作ることができます。
どうして、ここまでルールを単純にしたのですか。
私のようなモデルの規則を作るエンジニアからすれば、モデルの規則は次の3つを調整して作らなければなりません。
- ききめ(データモデルを作成して得られる効果)
- 単純性(単純な規則でデータモデルを作ることができる)
- 整合性(技術が理論的に矛盾しないで一貫している)
entityは2種類、関係の文法(規則)は4種類しかありません。もう少し増やせば表現力が豊かになるかもしれませんが、このバランスを考えることがデータモデルのポイントです。分厚い専門書を読まなければデータモデルを作成できないとか、作成するエンジニアによってデータモデルが異なるというのは変でしょう(笑)。なぜなら、モデルは「現実の写像」だし、現実は一つだから。
社内では先輩からよく業務処理やプログラミングのことは考えずにTMを描き、そのまま実装しなさいと言われます。ただ、ある部分は楽々Frameworkの準備された処理に当てはめることを考えてしまいます。やはり、「F-真」まで追求すればそれをそのまま実装すべきなのでしょうね。
これは2つのケースがあります。個別のSE独自の経験や判断でデータモデルを都合よく変更するのはアウトです。一方、現在、プログラムをスクラッチで組むことはほとんどありません。例えば楽々Frameworkのような超高速開発ツールがあって、そこに共通の明確な実装ポリシーがあれば、「F-真」をとった上で実装形態をツールに合わせて微調整することはかまいません。ただし、関係の文法である「L-真」は保証してください。
データモデルには、概念モデル(コンセプトモデル)、論理モデル、物理モデルがありますが、TMは論理モデルなのでしょうか。概念モデルを作成する必要はないのですか。
6ヵ月のRADのためであるときになぜ概念モデルがいるのでしょう。概念モデルは所詮論理モデルのドラフトです。TMを作ってしまえば概念モデルは要りません。現場ではロジカルデザインだけでいい。
佐藤正美さんはよく「TMはER図ではない」と言われていますが、なぜ、TMはER図ではないのですか。
「ER図」という言葉は使いたくないなあ。「TM図」と呼ぼう! ピーターチェンのER図では事業分析ができない、「F-真」をとれない。従って、ER図ではプログラミングが楽にならない。その他、ER図ではサブセットの解析もできない。
DOA(Data Oriented Approach)という言葉もありますね。TMもDOAのひとつですか。
僕はいつも「TMはDOAじゃない」って言っています。DOAという言葉は東京国際大学の堀内一先生(当時(株)日立製作所)が命名されましたが、その解釈はさまざまです。POA(Process Oriented Approach)の対立軸としてプログラムの都合は考えずデータモデリングする点ではTMもそうかもしれない。
ただ、前述したように、正規形をつくってER図を描いただけでは、「F-真」もわからないし、制約・束縛も網羅できないので開発が楽にならない。一方、ある人は「TMはオブジェクト指向だ」と言っています。確かにTMはプロセスまで見ているのでそうかもしれないと思うが、オブジェクト指向と言わないのは、データで済ませられるならデータでけりをつけたいからです。「事業をプログラミングする」際に、どこまでがデータで済ますことができるのかという境界線を明確に示したかったのです。
データモデリング上達のコツ
データモデルは事業構造を写像したものであり、システム開発において非常に重要な資料であるということが認識できました。でも、最近はビッグデータやIoTをベースとした開発が盛んで、プログラミングやアルゴリズムは学んでも、データモデリングを学ばない若手技術者が多いです。佐藤正美さんはどうお考えですか。
これは別の会合でも話題に出たけど、学校でも専門学校でも教えていないようですね。正直、えーって驚きました。
私もER図は習っていませんし、当社の他の若手も同様なようです。
20歳代のエンジニアであれば、それはしかたがないと思います。我々の仕事は「事業をプログラミングする」ことです。ですから、その年代でしたら、先ずプログラミングを身に着けるべきだし、企業の「事業」がどういうふうに営まれているのかを観察すべき年代でしょう。学生と20歳代のエンジニアに「事業に興味を持て」と言っても無理だと思う。プログラミングするためのデータベース設計があればいい。
30歳代になれば事業に興味が出る何かきっかけがあるのでしょうか。
30歳代になれば、プログラミングに興味があり、かつ実力もあるのでそのままプログラマーとしてやっていくか、あるいは、事業のほうに興味を抱いて、ユーザがいかにして事業を営んでいるのかを知りたいと思えば、「データベース」のほうに転職を自然に考えるでしょう。
ここで、「データベース」というのは、特定のプロダクトとしてのデータベースではなくて、ユーザが事業を営むために互いに「意味」を伝達している情報という共有語(記号)を集めたものを言っています。「データベース」に興味を持たなければ、データモデルに興味を持つことはできないでしょう。つまり、事業の「意味」に興味を抱かなければ、データモデルに興味を抱くことはできないということです。それができるようになるのは、30歳代でしょう。
30歳代はプログラマーからSEへの職種変換する時だからということですね。当社も含め、多くの会社は30歳ぐらいでSEになります。
年齢でSEをやれと言われてやるだけではだめです。やはり自分から事業に興味を持つ必要があります。往々にして、データモデルに興味を持っているが、事業には興味がないというSEがいますが、そういうSEが適切なデータモデルを作成することは、金輪際ないでしょう。
データモデリングのために事業に興味を持つとか、事業を知るとかいうのは具体的にどのようなことですか。個別の事業内容について詳しく知るということでしょうか。
経営、会計、生産管理などの一般的な業務の流れ知識でいい。企業特有の知識まではいりません。僕もクライアント企業の事業の細かい知識は知らないけれども、データモデルを見ればその企業の事業の流れが手に取るようにわかる。2時間もあれば初めてでもどんなことをやっているのかほとんどわかります。
佐藤正美さんは「SEの経験だけでデータベースを設計するな」と言われますが、データモデリング、及びTMが上達する方法を是非教えてください。
「技術」を売りにするエンジニアが「経験」を売りにしたらいけないでしょう(笑)。
データモデルは、先ほど言いましたが、「現実の写像(形式的構造)」です。ということは、データモデルを作成するために一番に大切なことは、「『論理』を使え」ということです。これはプログラミングでも同じでしょう。
「『論理』を使え」と言っても、事業を対象にしたデータモデルでは、難しい論理を使っている訳じゃない。ANDとORとNOTを使っているだけです。だから、データモデルは一見「論理回路図」ように見える。つまり、データモデルを作成するには、経験による先入観を捨てて、ユーザの事業に対して健全な「常識」(思考力)を使え、ということです。頭が目を騙すことが往々にしてある。
何か、効果的な訓練方法はありませんか。
TMを上達するコツは、「本稼働の」オンライン画面(データ項目数が20個以内が練習として望ましい)を対象にして、2人以上のエンジニアが相談しないでそれぞれデータモデルを作成して、結果を突き合わせてみることです。2人以上のエンジニアが作成しても「同じ」結果になるはずです。もし、それぞれのデータモデル上で違う部分があれば、「そのエンジニアの『解釈』」が違っているということなので、ズレている部分を互いに議論すればいい。この練習を1週間に1回、そして2ヶ月続ければいいでしょう。
結局のところ、エンジニア、DA(Data Analyst)が成長するポイントは2つしかありません。ちなみに、DAは、世間ではData Administratorの略語として使っていますが、私はData Analystの略語で使っています。ひとつは「情熱」、そしてもうひとつが「健全な常識」。すなわち、ロジカルに考えられること。特に「健全な常識」に関して最後は、数学力と英語力ですね。
えっ、数学と英語ですか?
優れたDAの条件はどこまで「F-真」を突き詰められるかという点につきます。一旦出来上がったデータモデルを見て、なぜなぜを繰り返して、現実をひとつひとつ論理的かつ網羅的に確認していく必要があります。人は過去の経験から思い込んでしまうと、見えるものも見えなくなります。思い込みを排し、論理的に判断していくという点で数学と似た面があります。
英語力はどう関係するのですか?
まず、「電車に乗っていて、窓から牛が見えた」という状況を思い浮かべてください。「牛が見えた」という言い方で何となくわかった気になりますが、「牛は何頭ですか?」、「それは今ですか昨日ですか?」、いろいろ思い浮かべられますね。日本語は細かいことは抜きに表現することができる言語です。一方、英語は数、時制、可能性に敏感な言語です。1頭か複数か、今か昨日かを考えないと喋れません。より具体的な状況を思考する力は英語を勉強すれば身につきます。「PCを買った」と聞けば、「何時?」、「何台?」と必ず意識するようになるのです。
もうひとつは思い込みを排除する批判力です。米国時代に見学したことのある教会の日曜学校では小さな子供を2つのグループに分けて反対の立場の意見を議論させていました。一方、日本の小学校ではある子の正解に対し、その子と同じと手を挙げた生徒を先生は「よくできました」と褒めます。これでは日本は勝てないと思いました。米国では正解であってもそれに対する反対意見を言う、すなわち批判することが重視されます。ディベートですね。そのような教育を物心ついたころから叩き込まれています。
実は私が批判的な考え方ができるようになったのは、ビル・トッテンさんの下で働いていた時です。ビル・トッテンさんも米国人です。ビル・トッテンさんは常に日本で初めてというような新しいことを始めるのですが、何かいいアイデアを思いつくと、逆の意見を私に求めてきます。そうやってそのアイデアを検証しているのです。
なるほど、英語力というよりも、欧米的な批判精神ということなのですね。ところで、佐藤正美さんの著書では集合論などの数学を記述した部分が多くありますね。また、TMには言語論や哲学も活用されているとも聞いています。その部分を読んでいるうちにわからなくなって挫折してしまいそうになることがあります。われわれSEは数学などの基礎理論をどこまで勉強すればいいのでしょうか。
拙著に数学や哲学の技術を書いているから、世間では勘違いされるのでしょうね(笑)。実は僕の本の読者は自分なのです。その時、その時考えたことを確認するために出版している。その都度、不足と思われるたびに新しい本を書いてきました。ああいう話は、上級者向け(つまり、モデル規則を作るエンジニア向け)です。だから、「現場でモデルを作成する」エンジニアは、数学・哲学の技術など知らなくていいですし、知る必要もない。
「現場でモデルを作成する」エンジニアに必要なのは、先入観を持たないこと(これ結構難しいですよ)、そして健全な「常識」(思考力)で考えることです。他の案件で成功したデータモデルだから、この案件に無条件に結果だけ当てはめてもだめ。先入観をもたずに集中することです。
それを聞いて安心しました(笑)。

データモデリングコンサルタントの業務
佐藤正美さんはこれまで数々の企業のデータモデリングのコンサルティングを行われていますが、いったい、データモデリングのコンサルティングというのはどのような仕事をされるのでしょうか。
さあー、いったい何やってんでしょうね。僕にもよくわからない(笑)。
最高のコンサルタントはそこにいるだけで、何もしないでも、メンバー達がデータモデルを作成して、ツールを使って情報システムを開発して仕事が進む。何も口出ししない。それでもメンバー達のやり方が従来とはあきらかに変わって進化している。それが、最高のコンサルタントだと考えています。
ただ、なかなかそうはいかないので、ちょこちょことこまめにDA(Data Analyst)を指導します。まず、出発点はデータモデルを作成すること。これがなければ仕事が始まらない。ところが、通常、ユーザから出てくるデータモデルは「L-真」までです。コンサルタントの仕事は、作成されたデータモデルを添削する、すなわち、「L-真」のデータモデルを「F-真」に変えていくことです。
佐藤正美さんはデータモデリングのプロフェッショナルであっても、顧客の事業の専門家ではありませんね。どうやって事実、すなわち「F-真」を引き出すことができるのですか。
基本的にはインタビューです。例えば、ユーザが作成したデータモデルから読める事業過程を声に出して説明し、ひとつひとつ確認をとっていきます。「ココとココは、こういう事業になっているけど、本当?」という風です。ユーザは事業過程を理解しているので、私が違うことを言えばわかります。違っていればデータモデルが違うということです。そして、「F-真」のモデルを作成したら、次の2点をユーザといっしょに検証します。
- モデル上に現れた(事業の)「強み・弱み」を確認する(モデルの構成条件)。
- 外部環境の変化に対応するために、モデルを変更する(モデルの環境条件)。
経営環境の変化に対応し競争に勝つために、現状のデータモデルにペンを入れていきます。
As-Isの「F-真」データモデルからTo-Beのデータモデルにしていくということですね。「F-真」は丁寧にインタビューすれば確認できるかもしれませんが、To-Beはどうやるのですか。
大抵の場合、経営者は次にどうするべきかを既に決めています。少なくとも僕が担当した大手のクライアントはすべてそうだった。コンサルタントはそれを実現するために情報システムに何が欠けているかを見つけ出すのです。
ないものを見つけ出すのは難しいように思えますが。
ひとつ例をあげてみましょう。ある全国展開のブランドが、売上低下に歯止めをかけるために地域密着型への経営変更方針を出し、それを実現するための販売管理システムを構築することになりました。その企業の事業過程で「地域コード」が使われていることがわかったのでしめしめと思ってエンティティ(リソース)を作ったのですが、右側に入る属性が何もなかった。地域コードは単に集計コードとして使われていただけだったのです。これでは地域密着型の販売管理システムなどできるわけがない。じゃあ、どうするのというわけです。
先ず、事業の構成条件を確認します。つまり、その「地域」エンティティに対して他のどのようなエンティティが関与(関係)しているか、あるいは関与させたほうがいいのかを考えます。事業のなかでの「地域」エンティティの在り方(座標)を考えます。次に、その事業の環境条件を考えます。つまり、「地域」エンティティの条件(アトリビュート)として、どのような条件(アトリビュート)を持っていれば、地域密着型の販売管理を実現できるのかということを考えます。事業の構成条件も環境条件も、事業環境の変化に対応するための「環境適応力」を模索することになります。
最終的に佐藤正美さんが何か具体的な提案をするのですか。
いえいえ、コンサルタントは主役になってはいけません。さりげなくDAに促して現場に疑問を投げかけさせるのです。戦うのはDAです。コンサルタントはキャタリスト(catalyst、媒体者)にすぎません。つまり、コンサルタントはユーザがやりたいことを速めるだけです。
DAを育成するのもコンサルタントの大きな仕事なのですね。
まさしくそうです。でも、2年も経てばDAは相当腕が上がるので、僕はほぼやることがなくなります。それでも、いざというときのためにしばらくは契約継続してもらえますが(笑)。
我々コンサルタントは、データ正規形を作ることのみが仕事じゃない。それはデータモデルを作成すれば自然に実現されることであって、コンサルタントの仕事は現実を写像したデータモデルを作成した後からが本格的な仕事です。まわりから見ると何をやっているかわかりにくい職業かもしれません。
TM最新事情
当初、T字形ER手法という名称だったのがある時からTMと変わりました。違いは何でしょうか。またTMの最新事情を教えてください。
これは、微妙な点ですね(笑)。一言でいえば、モデルの「前提」を変えた、ということです。だから、TMをデータ設計のためのモデルとしてのみ考えるのであれば──言い換えれば、「F-真」を重視しないで、「L-真」であればいい、と考えるのであれば──、T字形ER手法もTMも同じになるでしょう。
ただ、TMを事業分析かつデータ設計のためのモデルとして使うのであれば、T字形ER手法とは違ってきます。T字形ER手法には、「L-真」と「F-真」という考え方がなかった。
T字形ER手法は、いまだ、コッド正規形の影響が強かった。だから、T字形ER手法は、データベース設計技術であって、事業分析のための視点が(或る程度はあったけれど)弱かった。それを「分析=設計=実装」、つまり「現実を写像して、そのまま(というのは大袈裟で、論理を使って形式的構造にして)実装する」というのがTMです。
そして、TMはT字形ER手法の技術的不備をいくつか訂正しています──その重立った訂正点は、サブセット(特に、多重継承の問題)とヘッダー・ディテール構造(ファンクター、「関係」がそのままひとつのモノになる問題)です。
TMは、今、バージョン2.0です。そろそろ、バージョンを3.0に上げます。主な改善点は、「モデルは誰が作成しても同じになる」という謳い文句を「視点と共有語」という点から補強します。これも「前提」の変更であって、技術的に変更はないです。
何か、使い方が大きく変わるということはありますか。
いえ、考え方を補強しただけなので、データモデリングするSEにとっては大きな違いはないと思います。
リソースやイベントという名称も変わると聞いたのですが本当ですか。また、どうして名称を変えようと考えられたのですか。
名称は変えたかったのですが、実際問題として変更するのは大変なので変えないでおこうと思います。名称の変更については、例えば、エンティティをイベントとリソースに分けていますが、イベントは「出来事、行為、取引」という意味で良いとして、そのイベントに関与するモノをリソースとしたのはまずかったと思っています。というのは、イベントもやはり企業にとっての「リソース(資源)」なので名称が適切でないかなと。
名称が変わらないと聞いて安心しました。TM3.0の新しい本が出版されるのをお待ちしています。
本日はデータモデルについて貴重なお話を幅広くお聞かせいただきありがとうございました。システムを構築する上で実業務と構築したシステムの乖離がないようにすることは不可欠ですが、その具体的な手段として、データモデルをL-真から各業務の関係・制約・束縛の網羅をチェックしF-真をとるということとが印象的で、非常に参考になりました。
また、「企業のAs-Isのデータモデルから事業の強み、弱みを把握し、To-Beのデータモデルを模索する」というコンサルタントの業務をお聞きし、将来、自分自身がめざすべき業務の展望として非常に興味を持てました。直近の目標としてデータモデルを作成する際はこの対談を思い出し、F-真を追求していきたいと思います。
佐藤 正美氏 略歴・著書紹介

佐藤 正美(さとう まさみ)
株式会社エス・ディ・アイ代表
略歴:1979年、早稲田大学大学院商学研究科博士前期課程修了(財務会計論専攻)。アーサー・アンダーセン、等松青木監査法人および株式会社アシストを経て、1991年1月独立(株式会社SDI設立)、現在に至る。日本科学哲学会会員。
1980年代初期、わが国にRDB(リレーショナル・データベース)を初めて導入したエンジニアの一人。TM(T字形ER手法)を考案し、述べ百数十社に及ぶ大規模なデータベースづくりのコンサルティングを実施してきた。
主な著書
- 「CASEツール:機能解説と活用のノウハウ」、ソフト・リサーチ・センター、1989
- 「リポジトリ入門解説:技術体系と活用ガイド」、同、1991
- 「実践クライアント・サーバデータベース設計テクニック」、同、1993
- 「生産性を3倍にするRADによるデータベース構築技法」、同、1995
- 「T字形ERデータベース設計技法」、同、1998
- 「論理データベース論考:数学の基礎とT字形ER手法」、同、2000
- 「ITコンサルタントのスキル:なにをいかに学ぶか」、同、2003
- 「データベース設計論 T字形ER ~関係モデルとオブジェクト指向の統合をめざして~」、同、2005
- 「SEのためのモデルへのいざない:データモデルとは何か?」、同、2009